| |
Link Validator
1. Lancement de l'application
Cette application étant en Java, le lancement est un peu spécifique. Il est nécessaire d'exécuter le programme en ligne de commande.
Ligne de commande signifie :
pour les utilisateurs de Windows, lancement du DOS
pour les utilisateurs d'un Unix, lancement d'un terminal
...
Si vous avez des problèmes de navigation dans les répertoires et les disques, laissez un commentaire.
Si le programme se trouve, par exemple, dans le répertoire "c:\program files\internet\linkvalidator\Lv.class", il vous suffit
de saisir les commandes suivantes :
c:\> cd "c:\program files\internet"
c:\program files\internet> java linkvalidator.Lv
Pour les connaisseurs de java, la class Lv est la classe principale, c'est pour ca que je la lance par défaut !
2. Mode d'emploi
Voici une capture d'écran du link validator :
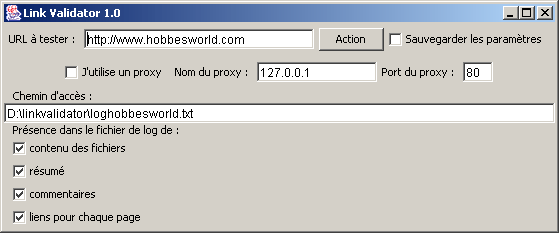
- Le champs correspondant à l'"URL à tester" est simplement l'adresse à partir de laquelle vous souhaitez faire la validation
des liens !
- Le bouton "Action" lance la recherche et la récupération des liens et leur validation
- La case à cocher "Sauvegarder les paramètres" permet d'enregistrer l'URL et les options d'utilisation pour qu'elles soient
automatiquement chargées au prochain lancement de l'application.
- La case à cocher "J'utilise un proxy" permet de préciser au Link Validator de se connecter à Internet via un proxy. Si vous
ne savez pas si vous utilisez un proxy, c'est que vous ne devez pas en utiliser. En général, seules les entreprises utilisent
un serveur proxy, une connexion internet personnelle n'en a pas. Les 2 paramètres suivants permettent de définir
le nom et le port du proxy pour établir la connexion.
- Le chemin d'accès correspond au nom du fichier dans lequel vous trouverez les résultats de l'analyse.
- Ensuite, on retrouve les options principales du fichier de log :
- contenu des fichiers : copie le code HTML récupéré pour chaque fichier analysé
- commentaires : affiche pour chaque page la liste des pages qui y font référence
- résumé : affiche la partie que je considère la plus importante, la syntaxe du résultat
- liens pour chaque page : affiche pour chaque page testée la liste des liens qui ont été trouvés dans la page.
Pour l'instant, l'interface n'évolue pas pendant l'analyse du site, mais plus tard, on devrait savoir beaucoup plus précisément où
on en est !
3. Exemple de fichier résultat
#############################################################
### LinkValidator ###
### HobbesWorld.com ###
#############################################################
Site : http://www.hobbesworld.com
Date : 04-09-2002
Traitement
Fichier : http://www.hobbesworld.com - (Premier fichier)
http://www.hobbesworld.com : 200
http://www.hobbesworld.com - ./images/std/logosml.gif : http://www.hobbesworld.com/images/std/logosml.gif
http://www.hobbesworld.com - ./images/puces/title.gif : http://www.hobbesworld.com/images/puces/title.gif
http://www.hobbesworld.com - ./films/index.php : http://www.hobbesworld.com/films/index.php
http://www.hobbesworld.com - ./bd/index.php : http://www.hobbesworld.com/bd/index.php
http://www.hobbesworld.com - ./livres/index.php : http://www.hobbesworld.com/livres/index.php
http://www.hobbesworld.com - ./musique/index.php : http://www.hobbesworld.com/musique/index.php
...
http://www.hobbesworld.com/index.php (200), fichier n° 0
http://www.hobbesworld.com/images/std/logosml.gif (200), fichier n° 1
http://www.hobbesworld.com/images/puces/title.gif (200), fichier n° 2
http://www.hobbesworld.com/films/index.php (200), fichier n° 3
http://www.hobbesworld.com/bd/index.php (200), fichier n° 4
http://www.hobbesworld.com/livres/index.php (200), fichier n° 5
http://www.hobbesworld.com/musique/index.php (200), fichier n° 6
- les 4 premières lignes sont toujours les mêmes
- ensuite, on a l'URL entrez dans la zone de saisie
- puis la date de l'analyse
- la partie suivante comporte les infos suivantes, retrouvées pour toutes les pages :
- le nom du fichier (Fichier : http://www.hobbesworld.com - (Premier fichier))
- le code de retour HTTP (http://www.hobbesworld.com : 200)
- le lien trouvé dans la page (http://www.hobbesworld.com - ./images/std/logosml.gif : http://www.hobbesworld.com/images/std/logosml.gif)
- enfin, le résumé qui affiche le nom de la page, puis son code de retour HTTP, et enfin le numéro du fichier. Ce numéro
est juste un compteur afin de mieux repérer le nombre de fichier.
Page modifiée le : 07/10/2024

| |
